
Context Is Everything
- Eric Kraus
- technology
- Dec 09, 2025
If you’ve ever tried to explain something complex to a six-year-old, you know the challenge: amazing curiosity but a very short attention span. Adults aren’t much different. And neither are Large Language Models.
The 50 First Dates Problem
LMs have a fundamental limitation that’s easy to overlook: they don’t store the state of your conversation.
Imagine your friend is in an accident and has rare amnesia - waking up every morning after the accident, forgetting everything that happened the day before - but remember everything before the accident. To help her catch up on life, you make a movie that she watches EVERY morning. That’s basically the plot of the 50 First Dates movie, conservatively avoiding any spoilers.
Now, imagine your friend lives a distance away. Instead of a movie, you write letters about events, changes in the world, etc. And she writes back reactions, thoughts, est. The problem is that any one letter won’t have enough information to make sense… so you have to include copies of all previous correspondence as well.
This works great until one of two inevitable problems occurs:
- Your box of letters gets full - you run out of space and have to start leaving out older messages, leading to confusion
- Information overload - soon there’s too much to read that your friend can’t process it all in time to respond meaningfully
This is exactly how the Context Window works with an AI model.
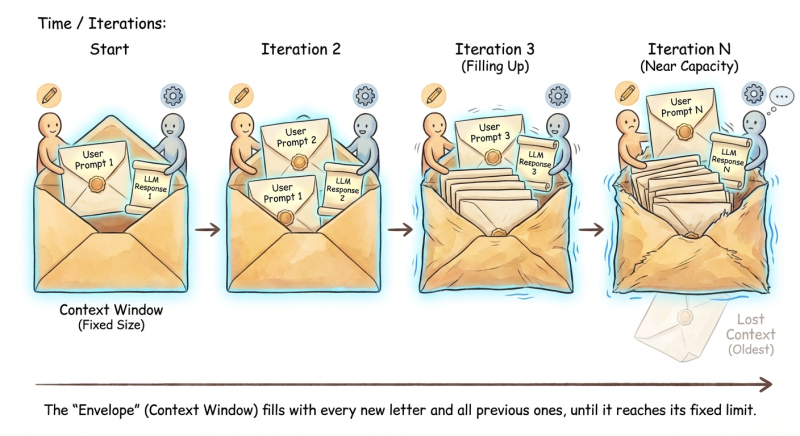
Context Window Overview
A context window is the maximum amount of text an LLM can process in a single “chat” conversation. It’s like the model’s focus i.e. everything unique to your request required to process and generate a meaningful response.
Here’s how it works in practice:
- Each time you send a new message, the entire conversation history gets sent along with it
- The LLM “replays” everything to catch up on context, then responds to your latest message
- Once you hit the limit, older messages get dropped to make room for new ones
Understanding Tokens
Context windows are measured in tokens . A token can be:
- A complete word: “hello” = 1 token
- Part of a word: “unthinkable” = “un” + “think” + “able” = 3 tokens
- Punctuation or spaces
Rule of thumb 1 token ≈ 0.75 words
Real-world examples:
- US Declaration of Independence: ~1,600 tokens
- Average email: ~200-500 tokens
- This blog post: ~2,000 tokens (20 blog posts = 40k tokens)
Model Context Window Limits
Context Windows, and AI landscape overall, is quite competitive and continuously evolving. As of time of publishing (December 2025):
- GPT-4: 128k tokens (~96k words)
- GPT-5.1: 400k tokens (~300k words)
- Sonnet 4: 200k tokens (~150k words)
- Sonnet 4.5: 1M tokens (~750k words)
- Gemini Pro 1.5, 2.5, 3: 1M tokens (~750k words)
Want to see exactly how your text gets tokenized? Try OpenAI’s Tokenizer tool .
What I’ve Learned About Managing Context
The Human Focus Sweet Spot
One of my super-powers is removing ambiguity from complex situations. The challenge is that everyone processes information differently, so knowing the right way to present information becomes an modern, information-age ‘art’ - which I continually strive to perfect.
With people and AI models, after a point, too much information becomes overwhelming. Even the most thoughtful clear explanation can have a revers effect.
Skills for the future
I believe ‘Understanding complex systems’ and ‘Ability to organize and explain process in simple terms’ will be two of the most critical and sought-after skills in the upcoming years.
The Context Window Sweet Spot
Here’s something many moderate AI users still don’t know and manage: AI models perform the best when instructions only utilize the first 40-50% of a context window. When messages start filling the last 40-50%, LLMs start to appear progressively “dumber”.
One might think a simple fix is to just: make bigger context windows!
Huge Context Windows
Unfortunately, bigger isn’t always better
50% of 1M tokens is 500k tokens (roughly 375k words). That is A LOT of text to read & process! (for a human OR AI) . So, even staying within the sweet spot (%) can still lead to confusion, if not managed well.
So, what are we to do?
Tips For Managing Context
Shoving more context into a prompt often has a reverse effect.
Here are three strategies that help manage the just right amount of context to send.
1. Pre-Process Raw Information (easy)
Tip: Distill raw information and extract important detail.
Instead of including an entire document with your prompt, summarize the document first. If you want to understand tone, key decisions, next steps, etc. - ask for that in your summary. You can often summarize content by 60-80%.
Then, utilize the first LLM’s response in a new chat with your prompt.
Think: “Does my instruction actually require the full text of a large document to respond?” Maybe. Often Not.
- Simple Workflow For Distilling Information
- Source
flowchart TD
A[Raw Text<br/>📄 Document] --> B{Full text <br/>required?}
B -->|No| C[New Chat Session]
B -->|Maybe| D[New Chat Session]
C --> E[Prompt to Summarize<br/>🔍 Extract key details<br/>~60-80% reduction]
E --> F[New Chat Session<br/>💬 Fresh context window]
F --> G[Prompt + Summary<br/>✅ Optimal performance]
G --> H[Managed Context<br/>✅ Optimal response]
D --> I[Prompt + Full Text<br/>⚠️ Risk: Context overflow]
I --> J[Large Context Usage<br/>❓ Potential degradation]
style A fill:#a7a7a7
style B fill:#6598A7
style C fill:#98BFA6
style D fill:#98BFA6
style E fill:#a7a7a7
style F fill:#98BFA6
style G fill:#a7a7a7
style H fill:#a7a1cc
style I fill:#DE7F80
Note: This technique is not needed for every request. “Write a response to this one-paragraph email”? You’ll be just fine executing that in a single prompt.
There are also ‘sub-agent’ capabilities with some models where you can instruct a parent agent to do this delegation for you
2. Strategic Tool Usage (medium)
Tip: Keep tactical, repetitive tasks out of your LLM responsibilities.
This goes hand in hand with Tip #1, but involves a bit more technical skill.
If part of the task you are asking AI to do is something that can be scripted, a tool may be a better, faster and cheaper choice.
- Converting CSV to JSON? → Use a Tool
- Extracting a paragraph’s meaning to structured data? → Perfect for an LLM
Think: “Am I asking something that requires thinking and decisions, or structured repetitive tasks?“
3. Architectural Solutions (advanced)
Tip: convert your AI model into an AI ‘agent’
This is definitely an avanced topic, but elements of this can be incorporated without
- RAG (Retrieval Augmented Generation): Pull in relevant context only when needed, from a library of documents
- Memory systems: Store important (commonly retreieved) information separately so it can be referenced as needed
- Sub-agents: Break complex tasks into focused, smaller conversations
The Bottom Line
More context isn’t better: better context is better.
Just like that conversation we have as humans, the magic happens when you’re concise, specific, and focused on what actually matters. Your AI interactions will be more effective, more reliable, and frankly, more human.


